Упорядоченный поиск
Упорядоченный поиск
На практике массивы элементов (записей) обычно определенным образом упорядочиваются. Это облегчает задачу поиска в них, так как появляется возможность формализации этого процесса. Записи в массиве в зависимости от значений ключевых полей могут быть упорядочены в числовом или лексикографическом поhядке.
Двоичный поиск
Этот вид поиска (программа prg10_242.asm) предназначен для выполнения поиска в упорядоченном массиве (записей), содержащем N числовых ключей: kl < k2 < <-. <kN. Упорядоченный массив чисел 02h, 04h, 06h, 08h, 16h, 24h, 38h, 45h, 47h, 48h, 56h, 57h, 58h, 70h, 76h, 79h можно представить в виде двоичного дерева (Рисунок 2.5).
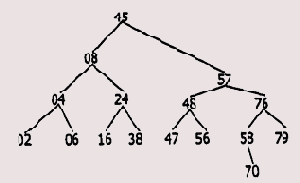
Рисунок 2.5. Представление массива в виде двоичного дерева
Для этого необходимо написать программу, которая в цикле выполняет следующие действия. Вначале определяется элемент, расположенный в середине исходного массива, — он будет вершиной двоичного дерева. Далее в стеке запоминаются интервалы ключей подмассивов, расположенных слева и справа от элемента-вершины двоичного дерева. После этого в цикле происходит извлечение интервалов ключей подмассивов из стека, определение серединных элементов в этих подмассивах, разбиение на очередные подмассивы, запоминание их границ в стеке, извлечение и т. д. В результате этих действий будет построено двоичное дерево, подобное изображенному на рисунке.
Абстрактно задачу поиска ключа с определенным значением К можно сравнить с обходом двоичного дерева начиная с его вершины. Если К меньше значения ключа вершины, то идем к узлу дерева по левой ветке, если больше — то по правой. Значение ключа в очередном узле соответствует среднему элементу под-массива, лежащему слева (справа) от элемента, соответствующего вершине дерева. Для среднего элемента подмассива процедура сравнения и принятия решения о переходе повторяется. Процесс заканчивается, когда обнаружен узел, ключ которого равен К, либо очередной узел является листом и идти больше некуда.
:prg10_242.asm - программа на ассемблере двоичного поиска
;Вход: mas[n] - упорядоченная последовательность двоичных значений длиной N
: к - искомое значение
:Выход: 1 - позиция в mas[n] (0<i<n-l), соответствующая найденному символу.
.data
; задаем массив
masdb 02h.04h.06h.08h.16h.24h.38h.45h.47h.48h.57h.56h.58h.70h.76h.79h
n-$-mas
k db 4 ;искомое значение
.code
в si и di индексы первого и последнего элементов последней просматриевой части
последовательности:
movsi.O .
mov di,n-l
хог ах. ах
nraval.k ;искомое значение в ах cont_search: ;получим центральный индекс:
cmpsi.di ;проверка на окончание (неуспешное):si>di
ja exit_bad
mov bx.si
addbx.di
shr bx.l ;делим на 2
cmpmas[bx].al сравниваем с искомым значением
je exit_good -.искомое значение найдено
ja @@ml ;mas[bx]>k
movsi.bx :mas[bx]<k:
inc si
jmpcont_search @@ml: movdi.bx
decdi
jmp cont_search exit_bad: пор :вывод сообщения об ошибке
exit_good: пор ;вывод сообщения об успехе
Двоичный поиск очень эффективен для поиска в предварительно отсортированном массиве. Другая возможность представления двоичного дерева — список. В списке каждый узел, кроме уникального ключа, содержит информационную часть и ссылки на последующий и, возможно, предыдущий элементы списка. Достоинство представления двоичного дерева в таком виде в том, что списком достаточно легко описывать дерево, в которое включаются и выключаются узлы. При представлении двоичного дерева в виде массива это сделать труднее. Ниже мы рассмотрим представление деревьев в программах на языке ассемблера.
